고정 헤더 영역
상세 컨텐츠
본문
컨볼루션 신경망(Convolution Neural Networks, CNN)
- 완전 연결 네트워크의 문제점으로부터 시작
- 매개변수의 폭발적인 증가
- 공간 추론의 부족: 픽셀 사이의 근접성 개념이 완전 연결 계층(Fully-Connected Layer)에서는 손실됨
- 동물의 시각피질(visual cortex, 視覺皮質)의 구조에서 영감을 받아 만들어진 딥러닝 신경망 모델
- 시각피질의 신경세포
- 시야 내의 특정 영역에 대한 자극만 수용
- 수용장(receptive field, 受容場)
- 해당 영역의 특정 특징에 대해서만 반응
- 시각 자극이 1차 시각피질을 통해서 처리된 다음, 2차 시각피질을 경유하여, 3차 시각피질 등 여러 영역을 통과하여 계층적인 정보처리
- 정보가 계층적으로 처리되어 가면서 점차 추상적인 특징이 추출되어 시각 인식
- 동물의 계층적 특징 추출과 시각인식 체계를 참조하여 만들어진 모델
- 전반부 : 컨볼루션 연산을 수행하여 특징 추출
- 후반부 : 특징을 이용하여 분류
- 영상분류, 문자 인식 등 인식문제에 높은 성능
컨볼루션 연산 (Convolution Operation)
- 필터(filter) 연산
- 입력 데이터에 필터를 통한 어떠한 연산을 진행
- 필터에 대응하는 원소끼리 곱하고, 그 합을 구함
- 연산이 완료된 결과 데이터를 특징 맵(feature map)이라 부름
- 필터(filter)
- 커널(kernel)이라고도 함
- 이미지 처리에서 사용하는 '이미지 필터'와 비슷한 개념
- 필터의 사이즈는 거의 항상 홀수
- 짝수이면 패딩이 비대칭이 되어버림
- 왼쪽, 오른쪽을 다르게 주어야함
- 중심위치가 존재, 즉 구별된 하나의 픽셀(중심 픽셀)이 존재
- 필터의 학습 파라미터 개수는 입력 데이터의 크기와 상관없이 일정
- 과적합을 방지할 수 있음
- 연산 시각화
- 일반적으로, 합성곱 연산을 한 후의 데이터 사이즈n: 입력 데이터의 크기
f: 필터(커널)의 크기
import numpy as np
from sklearn.datasets import load_sample_image
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
from tensorflow.keras.layers import Conv2D
flower = load_sample_image('flower.jpg')/255
print(flower.shape)
print(flower.dtype)
plt.imshow(flower)

conv = Conv2D(filters = 16, kernel_size=3, activation='relu')# 컨벌류셔널 신경망 코드
패딩(Padding)과 스트라이드(Stride)
- 필터(커널) 사이즈과 함께 입력 이미지와 출력 이미지의 사이즈를 결정하기 위해 사용
- 사용자가 결정할 수 있음
패딩(Padding)
- 입력 데이터의 주변을 특정 값으로 채우는 기법주로 0으로 많이 채움
- 출력 데이터의 크기
- 위 그림에서, 입력 데이터의 크기(n)는 5, 필터의 크기(f)는 4, 패딩값(p)은 2이므로 출력 데이터의 크기는 (5+2×2−4+1)=6
- (n+2p−f+1)×(n+2p−f+1)
- valid
- 패딩을 주지 않음
- padding=0은 0으로 채워진 테두리가 아니라 패딩을 주지 않는다는 의미
- same
- 패딩을 주어 입력 이미지의 크기와 연산 후의 이미지 크기를 같도록 유지
- 만약, 필터(커널)의 크기가 k 이면, 패딩의 크기는 p=k−12 (단, stride=1)
스트라이드(Stride)
- 필터를 적용하는 간격을 의미
- 아래 예제 그림은 간격이 2
출력 데이터의 크기
OH=H+2P−FHS+1
OW=W+2P−FWS+1
- 입력 크기 : (H,W)
- 필터 크기 : (FH,FW)
- 출력 크기 : (OH,OW)
- 패딩, 스트라이드 : P,S
- 위 식의 값에서 H+2P−FHS 또는 W+2P−FWS가 정수로 나누어 떨어지는 값이어야 함
- 정수로 나누어 떨어지지 않으면, 패딩, 스트라이드 값을 조정하여 정수로 나누어 떨어지게 해야함
[ ]
conv =Conv2D(filters=16, kernel_size=3, padding='same', strides=1, activation='relu')
풀링(Pooling)
- 필터(커널) 사이즈 내에서 특정 값을 추출하는 과정
맥스 풀링(Max Pooling)
- 가장 많이 사용되는 방법
- 출력 데이터의 사이즈 계산은 컨볼루션 연산과 동일OW=W+2P−FWS+1
- OH=H+2P−FHS+1
- 일반적으로 stride=2, kernel_size=2 를 통해 특징맵의 크기를 절반으로 줄이는 역할
- 모델이 물체의 주요한 특징을 학습할 수 있도록 해주며, 컨볼루션 신경망이 이동 불변성 특성을 가지게 해줌
- 예를 들어, 아래의 그림에서 초록색 사각형 안에 있는 2와 8의 위치를 바꾼다해도 맥스 풀링 연산은 8을 추출
- 모델의 파라미터 개수를 줄여주고, 연산 속도를 빠르게 함

from tensorflow.keras.layers import MaxPool2D
print(flower.shape)
flower = np.expand_dims(flower, axis=0)
print(flower.shape)
output = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(flower)
output = MaxPool2D(pool_size=2)(output)
print(output.shape)
plt.imshow(output[0,:,:,8], cmap='gray')
(427, 640, 3)
(1, 427, 640, 3)
(1, 213, 320, 32)

전역 평균 풀링(Global Avg Pooling)
- 특징 맵 각각의 평균값을 출력하는 것이므로, 특성맵에 있는 대부분의 정보를 잃음
- 출력층에는 유용할 수 있음
from tensorflow.keras.layers import GlobalAvgPool2D
print(flower.shape)
output = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(flower)
output = GlobalAvgPool2D()(output)
print(output.shape)
완전 연결 계층(Fully-Connected Layer)
- 입력으로 받은 텐서를 1차원으로 평면화(flatten) 함
- 밀집 계층(Dense Layer)라고도 함
- 일반적으로 분류기로서 네트워크의 마지막 계층에서 사용
from tensorflow.keras.layers import Dense
output_size =64
fc = Dense(units=output_size, activation='relu')
효 수용 영역(ERF, Effective Receptive Field)
- 입력 이미지에서 거리가 먼 요소를 상호 참조하여 결합하여 네트워크 능력에 영향을 줌
- 입력 이미지의 영역을 정의해 주어진 계층을 위한 뉴런의 활성화에 영향을 미침
- 한 계층의 필터 크기나 윈도우 크기로 불리기 때문에 RF(receptive field, 수용 영역)이라는 용어를 흔히 볼 수 있음
- RF의 중앙에 위치한 픽셀은 주변에 있는 픽셀보다 더 높은 가중치를 가짐
- 중앙부에 위치한 픽셀은 여러 개의 계층을 전파한 값
- 중앙부에 있는 픽셀은 주변에 위치한 픽셀보다 더 많은 정보를 가짐
- 가우시안 분포를 따름


CNN 모델 학습
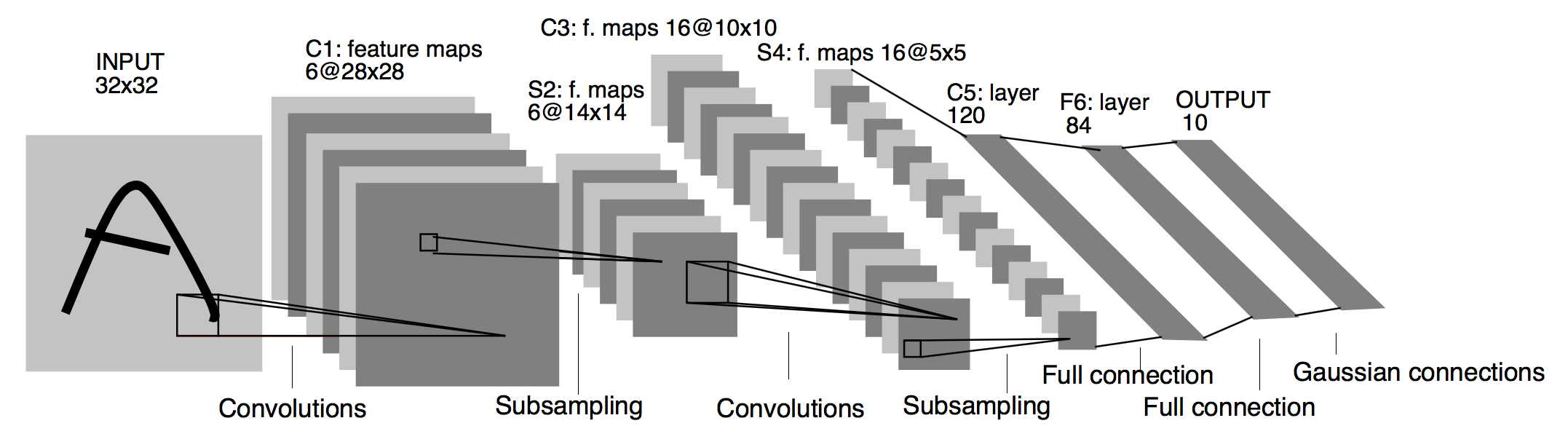
MNIST (LeNet)
- Yann LeCun 등의 제안(1998)
- 5 계층 구조: Conv-Pool-Conv- Pool-Conv-FC-FC(SM)
- 입력 : 32x32 필기체 숫자 영상 (MNIST 데이터)
- 풀링 : 가중치x(2x2블록의 합) + 편차항
- 시그모이드 활성화 함수 사용
- 성능: 오차율 0.95%(정확도: 99.05%)
from tensorflow.keras import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.callbacks import EarlyStopping, TensorBoard
from tensorflow.keras.datasets import mnist
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train[..., np.newaxis], x_test[..., np.newaxis]

모델 구성 및 컴파일
num_classes = 10
epochs =30
batch_size = 32
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense
from tensorflow.keras import Model
class LeNet5(Model):
def __init__(self, num_classes):
super(LeNet5, self).__init__()
self.conv1 = Conv2D(6, kernel_size=(5, 5), padding='same', activation='relu')
self.max_pool1 = MaxPool2D(pool_size=(2, 2))
self.conv2 = Conv2D(16, kernel_size=(5, 5), activation='relu')
self.max_pool2 = MaxPool2D(pool_size=(2, 2))
self.flatten = Flatten()
self.dense1 = Dense(120, activation='relu')
self.dense2 = Dense(84, activation='relu')
self.dense3 = Dense(num_classes, activation='softmax')
def call(self, input_data):
x = self.max_pool1(self.conv1(input_data))
x = self.max_pool2(self.conv2(x))
x = self.flatten(x)
x = self.dense3(self.dense2(self.dense1(x)))
return x
model = LeNet5(num_classes)
model.compile(optimizer ='sgd',
loss= 'sparse_categorical_crossentropy',
metrics=['accuracy'])
callbacks = [EarlyStopping(patience=3, monitor='val_loss'),
TensorBoard(log_dir='./logs', histogram_freq=1)]
이 코드는 케라스에서 모델 훈련 중에 실행되는 콜백(callback) 함수를 정의하는 것입니다. 첫 번째 콜백은 조기 종료(Early Stopping) 기능을 제공하여 검증 손실이 개선되지 않을 때 모델 훈련을 중지합니다. 두 번째 콜백은 TensorBoard 로그를 기록하여 모델의 훈련 및 검증 지표를 시각화합니다.
모델 학습 및 평가
model.fit(x_train, y_train,
batch_size= batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
callbacks=callbacks)


CNN 모델의 발전
- 1998: LeNet – Gradient-based Learning Applied to Document Recognition
- 2012: AlexNet – ImageNet Classification with Deep Convolutional Neural Network
- 2014: VggNet – Very Deep Convolutional Networks for Large-Scale Image Recognition
- 2014: GooLeNet – Going Deeper with Convolutions
- 2014: SppNet – Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 2015: ResNet – Deep Residual Learning for Image Recognition
- 2016: Xception – Xception: Deep Learning with Depthwise Separable Convolutions
- 2017: MobileNet – MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- 2017: DenseNet – Densely Connected Convolutional Networks
- 2017: SeNet – Squeeze and Excitation Networks
- 2017: ShuffleNet – ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- 2018: NasNet – Learning Transferable Architectures for Scalable Image Recognition
- 2018: Bag of Tricks – Bag of Tricks for Image Classification with Convolutional Neural Networks
- 2019: EfficientNet – EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
VGGNet(Visual Geometry Group Net)
- 2014년 ILSVRC에서 2등 차지 (상위-5 오류율: 7.32%), 이 후의 수많은 연구에 영향을 미침
- 특징
- 활성화 함수로 ReLU 사용, Dropout 적용
- 합성곱과 풀링 계층으로 구성된 블록과 분류를 위한 완전 연결계층으로 결합된 전형적인 구조
- 이미지 변환, 좌우 반전 등의 변환을 시도하여 인위적으로 데이터셋을 늘림
- 몇 개의 합성곱 계층과 최대-풀링 계층이 따르는 5개의 블록과, 3개의 완전연결계층(학습 시, 드롭아웃 사용)으로 구성
- 모든 합성곱과 최대-풀링 계층에 padding='SAME' 적용
- 합성곱 계층에는 stride=1, 활성화 함수로 ReLU 사용
- 특징 맵 깊이를 증가시킴
- 척도 변경을 통한 데이터 보강(Data Augmentation)
- 기여
- 3x3 커널을 갖는 두 합성곱 계층을 쌓은 스택이 5x5 커널을 갖는 하나의 합성곱 계층과 동일한 수용영역(ERF)을 가짐
- 11x11 사이즈의 필터 크기를 가지는 AlexNet과 비교하여, 더 작은 합성곱 계층을 더 많이 포함해 더 큰 ERF를 얻음
- 합성곱 계층의 개수가 많아지면, 매개변수 개수를 줄이고, 비선형성을 증가시킴
from keras.preprocessing import image
from keras.applications.vgg19 import VGG19, preprocess_input, decode_predictions
vggnet = VGG19(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
from tensorflow.keras.preprocessing.image import load_img, img_to_array
img = load_img('dog.jpg', target_size=(224, 224))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = vggnet.predict(x)
print(decode_predictions(preds))
1/1 [==============================] - 0s 32ms/step [[('n02088364', 'beagle', 0.83938146), ('n02089973', 'English_foxhound', 0.08834782), ('n02089867', 'Walker_hound', 0.06238833), ('n02088238', 'basset', 0.004565096), ('n02088632', 'bluetick', 0.0033394652)]]

GoogLeNet, Inception
- VGGNet을 제치고 같은 해 분류 과제에서 1등을 차지
- 인셉션 블록이라는 개념을 도입하여, 인셉션 네트워크(Inception Network)라고도 불림
- 특징
- CNN 계산 용량을 최적화하는 것을 고려
- 전형적인 합성곱, 풀링 계층으로 시작하고, 이 정보는 9개의 인셉션 모듈 스택을 통과 (해당 모듈을 하위 네트워크라고도 함)
- 각 모듈에서 입력 특징 맵은 서로 다른 계층으로 구성된 4개의 병렬 하위 블록에 전달되고, 이를 서로 다시 연결
- 모든 합성곱과 풀링 계층의 padding옵션은 'SAME'이며 stride=1 활성화 함수는 ReLU 사용
- 기여
- 규모가 큰 블록과 병목을 보편화
- 병목 계층으로 1x1 합성곱 계층 사용
- 완전 연결 계층 대신 풀링 계층 사용
- 중간 소실로 경사 소실 문제 해결
from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input
from tensorflow.keras.applications.inception_v3 import decode_predictions
inception = InceptionV3(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
img = load_img('fish.jpg', target_size=(299, 299))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = inception.predict(x)
print(decode_predictions(preds))
1/1 [==============================] - 2s 2s/step [[('n01443537', 'goldfish', 0.9748303), ('n02701002', 'ambulance', 0.0023265753), ('n02606052', 'rock_beauty', 0.0019084722), ('n02607072', 'anemone_fish', 0.00066402496), ('n09256479', 'coral_reef', 0.00043217686)]]

ResNet(Residual Net)
- 네트워크의 깊이가 깊어질수록 경사가 소실되거나 폭발하는 문제를 해결하고자 함
- 병목 합성곱 계층을 추가하거나 크기가 작은 커널을 사용
- 152개의 훈련가능한 계층을 수직으로 연결하여 구성
- 모든 합성곱과 풀링 계층에서 패딩옵셥으로 'SAME', stride=1 사용
- 3x3 합성곱 계층 다음마다 배치 정규화 적용, 1x1 합성곱 계층에는 활성화 함수가 존재하지 않음
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
resnet = ResNet50(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
img = load_img('bee.jpg', target_size=(224, 224))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = resnet.predict(x)
print(decode_predictions(preds))
1/1 [==============================] - 2s 2s/step [[('n02206856', 'bee', 0.9990995), ('n03530642', 'honeycomb', 0.0005614693), ('n02190166', 'fly', 0.00014320065), ('n02727426', 'apiary', 0.00010164116), ('n02219486', 'ant', 5.739578e-05)]]

Xception
- Inception module을 이용하여 depthwise convolution 적용
from tensorflow.keras.applications.xception import Xception, preprocess_input, decode_predictions
xception = Xception(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
img = load_img('beaver.jpg', target_size=(299, 299))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = xception.predict(x)
print(decode_predictions(preds))
/1 [==============================] - 4s 4s/step [[('n02363005', 'beaver', 0.82783943), ('n02361337', 'marmot', 0.059819862), ('n02493509', 'titi', 0.0044267923), ('n02442845', 'mink', 0.0024072072), ('n01883070', 'wombat', 0.0019868796)]]

MobileNet
- 성능보다 모델의 크기 또는 연산 속도 감소
- Depthwise conv와 Pointwise conv 사이에도 batch normalization과 ReLU를 삽입
- Conv layer를 활용한 모델과 정확도는 비슷하면서 계산량은 9배, 파라미터 수는 7배 줄임
from tensorflow.keras.applications.mobilenet import MobileNet, preprocess_input, decode_predictions
mobilenet = MobileNet(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
img = load_img('crane.jpg', target_size=(224, 224))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = mobilenet.predict(x)
print(decode_predictions(preds))
1/1 [==============================] - 1s 681ms/step [[('n03126707', 'crane', 0.960012), ('n03216828', 'dock', 0.029438736), ('n03240683', 'drilling_platform', 0.0051289774), ('n03344393', 'fireboat', 0.0026267502), ('n04366367', 'suspension_bridge', 0.0005006747)]]

DenseNet
- 각 층은 모든 앞 단계에서 올 수 있는 지름질 연결 구성
- 특징지도의 크기를 줄이기 위해 풀링 연산 적용 필요
- 밀집 블록(dense block)과 전이층(transition layer)으로 구성
- 전이층 : 1x1 컨볼루션과 평균값 풀링(APool)으로 구성
from tensorflow.keras.applications.densenet import DenseNet201, preprocess_input, decode_predictions
dnesnet = DenseNet201(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
img = load_img('zebra.jpg', target_size=(224, 224))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = dnesnet.predict(x)
1/1 [==============================] - 0s 149ms/step [[('n02391049', 'zebra', 0.93139124), ('n01518878', 'ostrich', 0.019752841), ('n02423022', 'gazelle', 0.011579038), ('n02397096', 'warthog', 0.004624992), ('n02422106', 'hartebeest', 0.0031486703)]]

NasNet
- 신경망 구조를 사람이 설계하지 않고, complete search를 통해 자동으로 구조를 찾아냄
- 네트워크를 구성하는 layer를 하나씩 탐색하는 NAS 방법 대신, NasNet은 Convolution cell 단위를 먼저 추정하고, 이들을 조합하여 전체 네트워크 구성
- 성능은 높지만, 파라미터 수와 연산량은 절반 정도로 감소
from tensorflow.keras.applications.nasnet import NASNetLarge, preprocess_input, decode_predictions
nasnet = NASNetLarge(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
img = load_img('notebook.jpg', target_size=(331, 331))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = nasnet.predict(x)
print(decode_predictions(preds))
[[('n03832673', 'notebook', 0.7930417), ('n03642806', 'laptop', 0.04842164), ('n04264628', 'space_bar', 0.034512542), ('n03085013', 'computer_keyboard', 0.020156916), ('n03777754', 'modem', 0.011370956)]]

EfficientNet
- EfficientNetB0인 작은 모델에서 주어진 Task에 최적화된 구조로 수정해나가는 형태
- 복잡한 Task에 맞춰 모델의 Capacity를 늘리기 위해 Wide Scaling, Deep Scaling, 그리고 Resolution Scaling을 사용
- EfficientNet은 Wide, Deep, Resolution을 함께 고려하는 Compound Scaling을 사용
from tensorflow.keras.applications.efficientnet import EfficientNetB1, preprocess_input, decode_predictions
efficientnet = EfficientNetB1(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
img = load_img('plane.jpg', target_size=(240, 240))
plt.imshow(img)
x = img_to_array(img)#이미지를 어레이 해줘야 이미지를 학습할수있다
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
preds = efficientnet.predict(x)
print(decode_predictions(preds))
[[('n02690373', 'airliner', 0.7587067), ('n04592741', 'wing', 0.100833364), ('n04552348', 'warplane', 0.082444966), ('n04266014', 'space_shuttle', 0.006341511), ('n02692877', 'airship', 0.00088756956)]]

'딥러닝 기초 이론 > 딥러닝 파이썬 실습' 카테고리의 다른 글
| LeNet model 구현해보기 (0) | 2023.02.15 |
|---|---|
| VGGNET 모델 tensorflow kreas로 구현하기 (0) | 2023.02.15 |
| Fashion_mnist.load_data로 케라스 튜너 사용해서 성능 높여보기 (0) | 2023.02.10 |
| 딥러닝으로 꽃 분류하기 (0) | 2023.02.10 |
| 3.MNIST 딥러닝 모델 예제 (0) | 2023.02.05 |




